Array
- https://docs.microsoft.com/ko-kr/dotnet/csharp/programming-guide/arrays/single-dimensional-arrays
- https://docs.microsoft.com/ko-kr/dotnet/api/system.array?view=net-5.0
특징
- 고정된 크기의 일차원 배열을 만든다.
- 배열은 관리되는 힙 메모리에 저장된다.
ArraySegment<T>
…
참고
.
특징
.
- 힙에 새로운 배열을 할당하지 않고, 이미 존재하는 배열의 일부를 참조할 수 있다.
- 인덱서를 통해 순회 참조할 수 있다.
foreach를 통해 순회 참조할 수 있다.- 세그먼트의 인덱서를 통해 내용을 변경할 경우, 참조 배열의 해당 위치의 값이 변경된다.
생성
.
1
2
3
4
5
6
7
int[] array = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
// 배열 전체 참조
ArraySegment<int> seg1 = new ArraySegment<int>(array);
// 인덱스 5부터 7까지 3칸 참조
ArraySegment<int> seg2 = new ArraySegment<int>(array, 5, 3);
프로퍼티
.
-
Array: 참조 중인 배열(읽기 전용) -
Offset: 참조하는 배열의 시작 인덱스 -
Count: 참조하는 배열 영역의 길이
메소드
.
Slice(int index)- 세그먼트의 특정 인덱스부터 끝까지 잘라내어 새로운 세그먼트를 생성한다.
Slice(int index, int count)- 세그먼트의 특정 인덱스부터 지정 길이만큼 잘라내어 새로운 세그먼트를 생성한다.
CopyTo(T[] dest)- 세그먼트의 내용을 대상 배열의 첫 인덱스 위치부터 세그먼트 길이만큼 복제한다.
CopyTo(T[] dest, int destIndex)- 세그먼트의 내용을 대상 배열의 지정 인덱스 위치부터 세그먼트 길이만큼 복제한다.
CopyTo(ArraySegment<T> dest)- 세그먼트의 내용을 대상 세그먼트에 복제한다.
- 세그먼트의 길이는 반드시
dest세그먼트의 길이보다 작거나 같아야 한다.
ToArray()- 세그먼트의 내용을 모두 복제하여 새로운 배열을 생성한다.
Span<T>
…
참고
.
- https://docs.microsoft.com/ko-kr/dotnet/api/system.span-1?view=net-5.0
- https://docs.microsoft.com/ko-kr/dotnet/csharp/language-reference/operators/stackalloc
- https://docs.microsoft.com/ko-kr/dotnet/api/system.runtime.interopservices.memorymarshal?view=net-5.0
- https://jacking75.github.io/NET_Span_5_Reasons_to_Use/
- https://m.blog.naver.com/oidoman/221677509349
특징
.
- 스택에 할당되는
readonly ref구조체 - 클래스 또는 구조체의 필드로 선언될 수 없다.
ArraySegment<T>에 비해 성능이 좋다.-
관리되는 힙, 관리되지 않는 힙, 스택의 배열을 모두 참조할 수 있다.
unsafe로만 가능했던 기능들을Span<T>을 통해 안전하게 구현할 수 있다.- 관리되는 힙 할당을 거쳐야만 했던 기능들을
Span<T>을 통해 힙 할당 없이 구현할 수 있다. MemoryMarshal의 지원을 통해 다양한 기능을 사용할 수 있다.- 인덱서를 통해
Span이 참조하고 있는 배열의 해당 위치의 값을 직접 수정할 수 있다.
생성
.
- 생성자 호출
1
2
3
4
5
6
7
int[] array = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
// 배열 전체에 대한 참조
Span<int> span1 = new Span<int>(array);
// 배열의 인덱스 5 ~ 7 참조
Span<int> span2 = new Span<int>(array, 5, 3);
- 배열 확장 메소드
1
2
3
4
5
6
7
8
9
10
// 전체
Span<int> span1 = array.AsSpan();
// 인덱스 5 ~ 끝까지
Span<int> span2 = array.AsSpan(startIndex: 5);
Span<int> span3 = array.AsSpan(start: 5);
// 인덱스 5부터 7까지
Span<int> span4 = array.AsSpan(start: 5, length: 3);
Span<int> span5 = array.AsSpan(range: 5..7);
MemoryMarshal을 통해 생성
1
2
// 인덱스 5부터 7까지 참조
Span<int> span = MemoryMarshal.CreateSpan(ref array[5], 3);
- 스택 배열 직접 생성
1
2
3
4
// 스택 메모리에 배열을 생성한다.
// 관리되지 않는 타입(값 타입)의 배열만 생성할 수 있다.
Span<int> span1 = stackalloc int[10];
Span<int> span2 = stackalloc int[] { 0, 1, 2, 3, 4, 5 };
프로퍼티
.
-
IsEmpty: 빈Span<T>인지 여부 -
Length:Span<T>이 가리키는 영역의 인덱스 길이
메소드
.
Clear()Span<T>이 참조하는 배열 영역의 값을 모두default로 초기화한다.
Fill(T value)Span<T>이 참조하는 배열 영역을 모두 지정한 값으로 초기화한다.
Slice(int start)Span<T>이 참조하던 영역의 인덱스 중start부터 끝까지 참조하는 새로운Span<T>을 생성하여 리턴한다.
Slice(int start, int length)Span<T>이 참조하던 영역의 인덱스 중start부터length길이만큼 참조하는 새로운Span<T>을 생성하여 리턴한다.
CopyTo(Span<T> dest)Span<T>이 참조하던 영역의 내용을dest가 참조하는 실제 영역에 복제한다.Span<T>의 길이는dest보다 작거나 같아야 한다.
TryCopyTo(Span<T> dest)CopyTo()와 같지만, 복제에 실패할 경우 예외를 발생시키지 않고false를 리턴한다.
ToArray()Span<T>이 참조하는 영역을 복제하여 새로운 배열을 생성한다.
확장 메소드
.
Reverse()Span<T>이 참조하는 영역의 내용을 뒤집는다.
Contains(T value)- 해당
Span<T>내에value가 포함되어 있는지 여부를bool타입으로 리턴한다.
- 해당
IndexOf(T value)- 해당
Span<T>내에서value가 존재하는 인덱스를 리턴한다. - 존재하지 않으면
-1을 리턴한다.
- 해당
IndexOf(ReadOnlySpan<T> sub)- 해당
Span<T>내에서sub영역과 일치하는 첫 인덱스를 리턴한다. - 일치하는 영역이 없으면
-1을 리턴한다. - 예시 :
.IndexOf(stackalloc int[] { 1, 2 })
- 해당
IndexOfAny(T a, T b)IndexOfAny(T a, T b, T c)IndexOfAny(ReadOnlySpan<T> values)- 해당
Span<T>에서 지정한 값들 중 하나라도 일치하는 값이 존재하는 첫 인덱스를 리턴한다.
- 해당
LastIndexOf():IndexOf()를 뒤에서부터 검사한다.LastIndexOfAny():IndexOfAny()를 뒤에서부터 검사한다.
ReadOnlySpan<T>
…
참고
특징
- 스택에 할당되는
readonly ref구조체 - 클래스 또는 구조체의 필드로 선언될 수 없다.
ReadOnlySpan의 인덱서는readonly이므로 값을 읽을 수만 있고 변경할 수는 없다.-
문자열과 같은 불변의 데이터 타입과 함께 동작하기에 용이하다.
- 변환, 복사 등의 연산에서
Span<T>와 API가 겹치는 경우가 빈번한데, 성능 차이는 없다.
프로퍼티, 메소드
-
.Clear(),.Fill()과 같이 내부를 변경하는 메소드는 존재하지 않는다. -
대부분
Span<T>와 API가 같다.
Memory<T>
…
참고
.
- https://docs.microsoft.com/ko-kr/dotnet/api/system.memory-1?view=net-5.0
- https://www.sysnet.pe.kr/2/0/12475
- https://antao-almada.medium.com/how-to-use-span-t-and-memory-t-c0b126aae652
- https://docs.microsoft.com/en-us/archive/msdn-magazine/2018/january/csharp-all-about-span-exploring-a-new-net-mainstay
특징
.
Span<T>처럼 배열의 일부를 참조할 수 있는readonly구조체Span<T>과 달리, 클래스 또는 구조체의 필드로 사용될 수 있으며 힙에 저장될 수 있다.-
프로퍼티로
.Span을 통해 동일 영역에 대한 Span을 참조할 수 있다. []를 통한 인덱싱을 할 수 없다.foreach를 통한 순회를 할 수 없다.
생성
.
- 생성자 호출
1
2
3
4
int[] array = new int[10] { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
Memory<int> memory1 = new Memory<int>(array);
Memory<int> memory2 = new Memory<int>(array, 5, 3);
- 배열 확장 메소드
1
2
3
4
5
6
7
8
9
10
// 전체
Memory<int> memory1 = array.AsMemory();
// 인덱스 5 ~ 끝까지
Memory<int> memory2 = array.AsMemory(startIndex: 5);
Memory<int> memory3 = array.AsMemory(start: 5);
// 인덱스 5부터 7까지
Memory<int> memory4 = array.AsMemory(start: 5, length: 3);
Memory<int> memory5 = array.AsMemory(range: 5..3);
MemoryMarshal을 통해 생성
1
2
// 인덱스 5부터 7까지 참조
Memory<int> memory = MemoryMarshal.CreateFromPinnedArray(array, 5, 3);
프로퍼티
.
-
IsEmpty: 빈Memory<T>인지 여부 -
Length:Memory<T>가 가리키는 영역의 인덱스 길이 -
Span: 동일 참조에 대한Span<T>리턴
메소드
.
Pin()Memory<T>에 대한 참조 핸들을System.Buffer.MemoryHandle타입으로 리턴한다.
Slice(int start)Memory<T>가 참조하던 영역의 인덱스 중start부터 끝까지 참조하는 새로운Memory<T>를 생성하여 리턴한다.
Slice(int start, int length)Memory<T>가 참조하던 영역의 인덱스 중start부터length길이만큼 참조하는 새로운Memory<T>를 생성하여 리턴한다.
CopyTo(Memory<T> dest)Memory<T>가 참조하던 영역의 내용을dest가 참조하는 실제 영역에 복제한다.Memory<T>의 길이는dest보다 작거나 같아야 한다.
TryCopyTo(Memory<T> dest)CopyTo()와 같지만, 복제에 실패할 경우 예외를 발생시키지 않고false를 리턴한다.
ToArray()Memory<T>가 참조하는 영역을 복제하여 새로운 배열을 생성한다.
ReadOnlyMemory<T>
…
참고
특징
Memory<T>의 읽기 전용 버전ReadOnlySpan<T>과 달리, 클래스 또는 구조체의 필드로 사용될 수 있으며 힙에 저장될 수 있다.- 프로퍼티로
.Span을 통해 동일 영역에 대한 ReadOnlySpan을 참조할 수 있다.
프로퍼티, 메소드
Memory<T>와 동일하다.
Span<T>의 다양한 활용
[1] 배열의 내용 복제하기
.
1
Array.Copy(from, offset, to, offset, length);
위 방식보다
1
2
3
4
5
new Span<byte>(from, offset, length).CopyTo(new Span<byte>(to, offset, length));
// 또는
from.AsSpan(offset, length).CopyTo(to.AsSpan(offset, length));
이 방식이 더 빠르다.
복제할 길이가 짧을수록 격차는 더 크다.
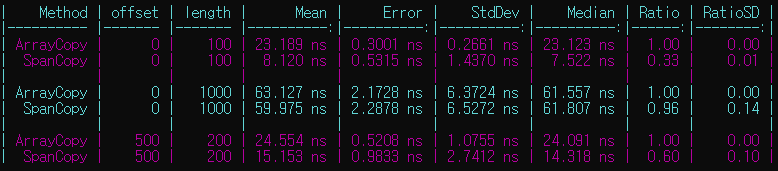
[2] 관리되지 않는 타입들을 byte[]로 변환하기
.
1
2
3
4
5
6
7
8
9
10
11
12
byte[] buffer = new buffer[1024];
float data = 1234f;
int offset = 120;
// (1)
ReadOnlySpan<byte> bSpan = MemoryMarshal.AsBytes(stackalloc[] { data });
bSpan.CopyTo(new Span<byte>(buffer, offset, bSpan.Length));
// (2)
ReadOnlySpan<float> fSpan = MemoryMarshal.CreateReadOnlySpan(ref data, 1);
ReadOnlySpan<byte> bSpan = MemoryMarshal.Cast<float, byte>(fSpan);
bSpan.CopyTo(new Span<byte>(buffer, offset, sizeof(float)));
-
BitConverter.GetBytes()와 동일한 기능을 수행하지만, 훨씬 빠르고 힙 메모리 할당이 없다. - 값 타입들을 크기에 맞게
ReadOnlySpan<byte>로 변환하고, 목표byte[]배열에 복사한다. - 벤치마크 결과
(1)보다(2)의 방식이20%~30%더 빨랐다.
[3] byte[]로부터 목표 타입으로 값 변환하기
.
- 공통 환경
1
2
3
4
5
6
7
byte[] buffer = new byte[1024];
int offset = 123;
float data = 123.456f;
float destValue;
// buffer의 offset 인덱스부터 4칸에 123.456 값 집어넣기
MemoryMarshal.AsBytes(stackalloc[] { data }).CopyTo(new Span<byte>(buffer, offset, 4));
BitConverter사용
1
2
3
4
5
// (1)
destValue = BitConverter.ToSingle(buffer, offset);
// (2)
destValue = BitConverter.ToSingle(new ReadOnlySpan<byte>(buffer, offset, 4));
MemoryMarshal사용
1
2
3
4
5
6
7
// (3)
ReadOnlySpan<float> fSpan =
MemoryMarshal.Cast<byte, float>(new ReadOnlySpan<byte>(buffer, offset, 4));
destValue = fSpan[0];
// (4)
destValue = MemoryMarshal.Read<float>(new ReadOnlySpan<byte>(buffer, offset, 4));
- 위의 4가지 벤치마크 결과

- 결론
BitConverter보다MemoryMarshal이 훨씬 빠르다.BitConverter의 두 방식은 큰 차이는 없으나(1)이 조금 더 빠르다.MemoryMarshal의 두 방식은 속도 차이가 없다.
[4] 부분 문자열 만들기
.
1
2
string str = "abcde01234";
string subStr = str.Substring(2, 4);
위와 같이 .Substring()을 통해 문자열을 자르면
해당 길이만큼 새롭게 힙에 할당된 문자열이 생성된다.
1
ReadOnlySpan<char> charSpan = str.AsSpan(2, 4);
이렇게 ReadOnlySpan<char>로 받으면
할당 없이 부분 문자열을 받을 수 있다.
1
2
3
4
5
6
7
8
// byte[] buffer;
// int offset;
int strLen =
Encoding.UTF8.GetBytes(
charSpan,
new Span<byte>(buffer, offset, charSpan.Length * 4)
);
심지어 이렇게 ReadOnlySpan<char>를 그대로 인코딩하여 byte[] 배열에 옮겨줄 수도 있고
1
2
3
4
5
6
Span<char> charSpan2 = stackalloc char[strLen];
Encoding.UTF8.GetChars(
new ReadOnlySpan<byte>(buffer, offset, strLen),
charSpan2
);
문자열이 인코딩된 ReadOnlySpan<byte>를 다시 디코딩하여
Span<char>에 옮겨줄 수도 있다.
그리고 역시 이 모든 과정에서 힙 메모리 할당량은 0이다.
[5] 문자열을 구분자로 나누어 정수로 파싱하기
.
1
2
3
4
5
6
7
string str = "12,345,6789";
string[] strArr = str.Split(',');
int[] intArr = new int[strArr.Length];
for (int i = 0; i < intArr.Length; i++)
{
int.TryParse(strArr[i], out intArr[i]);
}
특정 문자를 기준으로 문자열을 나눈다.
위의 경우 크기가 3인 스트링 배열이 생성되며,
배열 내 각각의 문자열을 int로 변환한다.
참고로 이 경우에 할당되는 힙 메모리 크기는 184 바이트이며,
그 중 str.Split()으로 인해 할당되는 크기는 144 바이트이다.
원하는 것은 변환된 정수들일 뿐인데,
중간에 생성되는 string[]과 그 문자열들이 불필요하게 힙에 할당되고 있는 것이다.
1
2
3
4
5
6
7
8
9
10
string str = "12,345,6789";
ReadOnlySpan<char> charSpan = str.AsSpan();
var charSpan1 = charSpan[0..1];
var charSpan2 = charSpan[3..5];
var charSpan3 = charSpan[7..^0];
int.TryParse(charSpan1, out int i1);
int.TryParse(charSpan1, out int i2);
int.TryParse(charSpan1, out int i3);
이렇게 ReadOnlySpan<char>을 생성하고 영역을 나누어 파싱하면
힙 할당 없이 스트링으로부터 정수들을 파싱할 수 있다.
하지만 다양한 형태의 스트링에 대응할 수 없으므로,
일반화하여 구현한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
public static class StringParseExtension
{
public static IntParseResult SplitAndParseToInt(this string @this, char seperator)
{
return new IntParseResult(@this.AsSpan(), seperator);
}
}
public ref struct IntParseResult
{
public int Current { get; private set; }
private readonly char seperator;
private ReadOnlySpan<char> charSpan;
public IntParseResult(ReadOnlySpan<char> span, char seperator)
{
this.charSpan = span;
this.seperator = seperator;
Current = default;
}
public IntParseResult GetEnumerator()
{
return this;
}
public bool MoveNext()
{
int len = charSpan.Length;
if (len == 0) return false;
// 1. 숫자 시작지점 찾기
int startOfNumber = charSpan.IndexOf(seperator);
// 첫 문자가 seperator에 해당하는 경우,
// seperator가 아닌 문자(숫자)를 찾을 때까지 인덱스 순회
if (startOfNumber == 0)
{
for (startOfNumber++; startOfNumber < len; startOfNumber++)
{
if (charSpan[startOfNumber] != seperator)
break;
}
if (startOfNumber >= len)
return false;
charSpan = charSpan.Slice(startOfNumber);
}
// 2. 숫자 끝지점 찾기
int endOfNumber = charSpan.IndexOf(seperator);
int wordLen = endOfNumber == -1 ? charSpan.Length : endOfNumber;
bool success = int.TryParse(charSpan.Slice(0, wordLen), out int number);
if (!success)
return false;
// 숫자 할당
Current = number;
// 3. 다음 Span 할당
charSpan = endOfNumber == -1 ? ReadOnlySpan<char>.Empty : charSpan.Slice(wordLen);
return true;
}
}
위와 같이 구현하고,
1
2
3
4
5
6
7
8
9
string str = "123,456,789";
var parseResult = str.SplitAndParseToInt(',');
Console.WriteLine(str);
int i = 0;
foreach (var item in parseResult)
{
Console.WriteLine($"[{i++}] {item}");
}
이렇게 테스트해볼 수 있다.
그리고 string.Split()과의 성능 비교 벤치마크 결과는 다음과 같다.
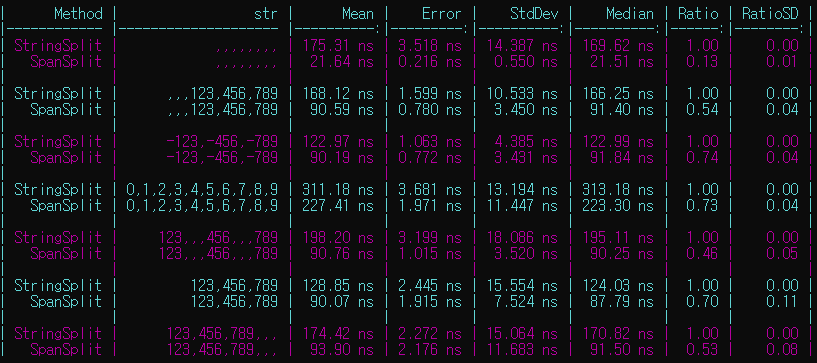
문자열에 들어가는 숫자의 개수에 따라 다시 벤치마크 해보니
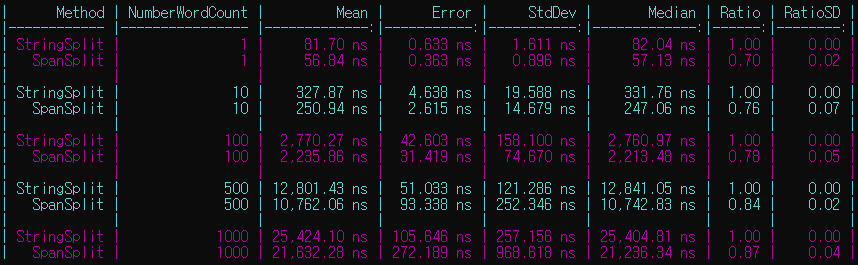
이런 결과가 나왔다.
성능도 항상 더 좋은데다가 힙 할당도 없으니 나름 괜찮은 성과라고 할 수 있다.
참고 :
https://www.meziantou.net/split-a-string-into-lines-without-allocation.htm