Curiosity
타입별로 GetHashCode()의 성능 비용이 얼마나 달라지는지 간단히 확인해본다.
사용자 정의 타입은 GetHashCode() 메소드를 임의로 오버라이드 하지 않고 확인한다.
사용자 정의 타입
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public struct Struct1 { }
public struct Struct2
{
public int a, b, c, d, e, f, g;
public long A, B, C, D, E, F, G, H;
}
public struct Struct3
{
public int i1, i2, i3, i4, i5, i6, i7, i8;
public long l1, l2, l3, l4, l5, l6, l7, l8;
public double d1, d2, d3, d4, d5, d6, d7, d8;
}
public class Class1 { }
public class Class2
{
public int a, b, c, d, e, f, g;
public long A, B, C, D, E, F, G, H;
}
public class Class3
{
public int i1, i2, i3, i4, i5, i6, i7, i8;
public long l1, l2, l3, l4, l5, l6, l7, l8;
public double d1, d2, d3, d4, d5, d6, d7, d8;
}
벤치마크 대상 타입
- 구조체
- 정수 :
int(값의 크기에 따라 2가지),long - 실수 :
float,double - 임의의 구조체 :
Struct1,Struct2,Struct3
- 정수 :
- 클래스
- 문자열 :
string(길이가 다른 문자열 2가지) - 임의의 클래스 :
Class1,Class2,Class3
- 문자열 :
Benchmark
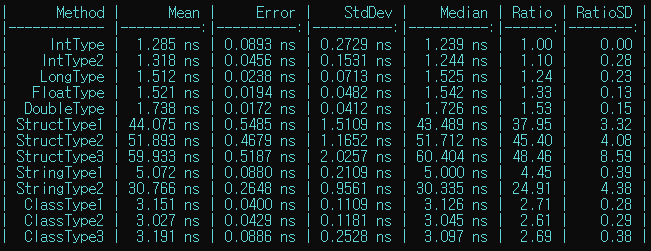
결론
-
정해진 크기의 객체에 대해, 저장된 값이 계산 비용에 영향을 주지는 않는다.
-
GetHashCode()메소드를 오버라이드 하지 않은 구조체 타입은 계산 비용이 매우 크다. -
구조체 타입은 객체의 크기에 비례하여 비용이 증가한다.
-
클래스 타입은 타입이 달라도 비용이 같거나 비슷하다.
-
string타입은 문자열이 길어질수록 비용이 증가한다.
추가
구조체 타입의 계산 비용이 큰 이유?
아무래도 박싱 때문이지 않을까 하고
구조체의 GetHashCode()를 호출하는 부분의 CIL을 열어봤더니
boxing은 보이지 않고
1
2
IL_000b: constrained. Struct1
IL_0011: callvirt instance int32 [System.Runtime]System.Object::GetHashCode()
이렇게 callvirt로 GetHashCode()를 호출하는 것만 확인할 수 있었다.
그래서 어셈블리 코드를 열어보니
1
2
3
4
5
6
7
8
9
10
11
12
13
int a = s1.GetHashCode();
00007FFC23C50D36 lea rdx,[rbp+40h]
00007FFC23C50D3A mov rcx,7FFC23D22678h
00007FFC23C50D44 call CORINFO_HELP_BOX (07FFC83767880h)
00007FFC23C50D49 mov qword ptr [rbp+28h],rax
00007FFC23C50D4D mov rcx,qword ptr [rbp+28h]
00007FFC23C50D51 mov rax,qword ptr [rbp+28h]
00007FFC23C50D55 mov rax,qword ptr [rax]
00007FFC23C50D58 mov rax,qword ptr [rax+40h]
00007FFC23C50D5C call qword ptr [rax+18h]
00007FFC23C50D5F mov dword ptr [rbp+34h],eax
00007FFC23C50D62 mov eax,dword ptr [rbp+34h]
00007FFC23C50D65 mov dword ptr [rbp+3Ch],eax
이 중에서
1
call CORINFO_HELP_BOX (07FFC84F07880h)
이렇게 의심 가는 부분을 찾을 수 있었고,
결론적으로 성능 저하의 원인은 박싱이 맞았다.
구조체에 GetHashCode()를 오버라이드하여 작성했을 때는 박싱이 발생하지 않는 것을 확인했다.
1
2
3
4
5
6
int a = s1.GetHashCode();
00007FFC23C60D33 lea rcx,[rbp+30h]
00007FFC23C60D37 call CLRStub[MethodDescPrestub]@7ffc23c60668 (07FFC23C60668h)
00007FFC23C60D3C mov dword ptr [rbp+24h],eax
00007FFC23C60D3F mov eax,dword ptr [rbp+24h]
00007FFC23C60D42 mov dword ptr [rbp+2Ch],eax
그래서, 동일한 필드를 가진 두 구조체에 대해
한 구조체는 GetHashCode()를 오버라이드 하지 않고
다른 구조체는 오버라이드하여 다시 벤치마크를 비교해보았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
public struct Struct1
{
public int a, b, c, d;
}
public struct Struct2
{
public int a, b, c, d;
public override int GetHashCode()
{
return a.GetHashCode() + b.GetHashCode() + c.GetHashCode() + d.GetHashCode();
}
}

역시 박싱은 언제나 성능 저하의 원흉이다.
구조체와 클래스의 해시 계산 방식
클래스는 기본적으로 객체의 주소를 이용해 해시를 계산한다.
따라서 GetHashCode를 따로 오버라이드 하지 않으면 내부 필드는 해시 계산에 관여하지 않는다.
구조체는 GetHashCode()를 오버라이드 하지 않은 경우에도,
내부의 필드들을 이용하여 해시를 계산한다.
따라서, 변수가 달라도 구조체 필드의 값이 모두 같다면 같은 해시 코드를 출력한다.
1
2
3
4
private class Data
{
public int a, b;
}
위와 같은 사용자 정의 타입에 대해,
1
2
3
4
5
6
7
8
9
10
Data d1 = new Data();
Data d2 = new Data();
d1.a = d2.a = 1;
d1.b = d2.b = 2;
Dictionary<Data, int> dict = new Dictionary<Data, int>();
dict.Add(d1, 100);
int foundValue = dict[d2];
이렇게 두 객체를 만들고 필드 값을 서로 일치시킨다.
Data가 클래스이면 당연히 위 코드의 마지막 줄은 KeyNotFoundException이 발생한다.
하지만 구조체는 d1을 키로 저장했던 값인 100을 참조하게 된다.
그렇다면 클래스 타입에서 GetHashCode()를 오버라이드하여
1
2
3
4
5
6
7
8
9
private class Data
{
public int a, b;
public override int GetHashCode()
{
return a.GetHashCode() + b.GetHashCode();
}
}
내부 필드들의 값이 모두 같을 때 같은 해시 코드를 출력하도록 한다면
필드 값이 모두 같은, 다른 객체의 키에 대해 딕셔너리가 같은 값을 주지 않을까?
안된다.
클래스 타입은 GetHashCode()를 위와 같이 오버라이드 해도
딕셔너리가 같은 해시 값의 서로 다른 객체에 대해 동일 값을 참조시켜 주지는 않는다.
이유를 찾기 위해 디컴파일하여 Dictionary<TKey, TValue> 구현부를 확인하고,
다음과 같은 코드를 찾을 수 있었다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// System.Collections.Generic.Dictionary<TKey,TValue>
private int FindEntry(TKey key)
{
if (key == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets != null)
{
int num = comparer.GetHashCode(key) & 0x7FFFFFFF;
for (int num2 = buckets[num % buckets.Length]; num2 >= 0; num2 = entries[num2].next)
{
if (entries[num2].hashCode == num && comparer.Equals(entries[num2].key, key))
{
return num2;
}
}
}
return -1;
}
여기서 주목해야 할 부분은
1
if (entries[num2].hashCode == num && comparer.Equals(entries[num2].key, key))
이부분이다.
키의 해시코드가 같다고 무조건 같은 값을 참조하는 것이 아니라,
IEqualityComparer<TKey> 타입의 Default Comparer를 통해
.Equals()를 검사한다는 것을 알 수 있다.
int, string 타입의 GetHashCode() 들여다보기
int 타입의 GetHashCode()는 왜 그렇게 빠르고,
string 타입의 GetHashCode()는 왜 문자열 길이에 따라 느려지는 걸까?
구현을 확인해보면 빠르게 이해할 수 있다.
1
2
3
4
5
6
7
// System.Int32
[__DynamicallyInvokable]
public override int GetHashCode()
{
return this;
}
우선, int 타입의 GetHashCode()이다.
그냥 자신을 리턴한다.
빠른 이유 바로 납득.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
// System.String
[SecuritySafeCritical]
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.MayFail)]
[__DynamicallyInvokable]
public unsafe override int GetHashCode()
{
if (HashHelpers.s_UseRandomizedStringHashing)
{
return InternalMarvin32HashString(this, Length, 0L);
}
fixed (char* ptr = this)
{
int num = 5381;
int num2 = num;
char* ptr2 = ptr;
int num3;
while ((num3 = *ptr2) != 0)
{
num = ((num << 5) + num) ^ num3;
num3 = ptr2[1];
if (num3 == 0)
{
break;
}
num2 = ((num2 << 5) + num2) ^ num3;
ptr2 += 2;
}
return num + num2 * 1566083941;
}
}
string 타입의 GetHashCode() 구현부이다.
int에 비하면 아주 휘황찬란하게 구현되어 있는 모습이 보인다.
char*포인터를 이동하여 문자열 내부를 순회하며 해시 코드를 계산한다.
따라서 문자열 길이가 길어질수록 계산 비용은 증가한다는 것을 확인할 수 있다.