목차
- 1. GetComponent(), Find() 메소드 사용 줄이기
- 2. GetComponent() 대신 TryGetComponent() 사용하기
- 3. Object.name, GameObject.tag 사용하지 않기
- 4. 비어있는 유니티 이벤트 메소드 방치하지 않기
- 5. StartCoroutine() 자주 호출하지 않기
- 6. 코루틴의 yield 캐싱하기
- 7. 메소드 호출 줄이기
- 8. 참조 캐싱하기
- 9. 빌드 이후 Debug.Log() 사용하지 않기
- 10 Transform 변경은 한번에
- 11. 불필요하게 부모 자식 구조 늘리지 않기
- 12. ScriptableObject 활용하기
- 13. 필요하지 않은 경우, 리턴하지 않기
- 14. new로 생성하는 부분 최대한 줄이기
- 15. 오브젝트 풀링 사용하기
- 16. 구조체 사용하기
- 17. 컬렉션 재사용하기
- 18. List 사용할 때 주의할 점
- 19. StringBuilder 사용하기
- 20. LINQ 사용 시 주의하기
- 21. 박싱, 언박싱 피하기
- 23. Enum HasFlag() 박싱 이슈
- 24. 비싼 수학 계산 피하기
- 25. Camera.main
- 26. 벡터 연산 시 주의사항
GetComponent(), Find() 메소드 사용 줄이기
GetComponent, Find, FindObjectOfType 등의 메소드는 자주 호출될 경우 성능에 악영향을 끼친다.
따라서 객체 참조가 필요할 때마다 Update()에서 Get, Find 메소드들을 호출하는 방식은 지양하고,
최대한 Awake, Start 메소드에서 Get, Find 메소드들을 통해 객체들을 필드에 캐싱하여 사용해야 한다.
- 예시
1
2
3
4
private void Update()
{
GetComponent<Rigidbody>().AddForce(Vector3.right);
}
위와 같은 코드가 있다면, 아래처럼 바꾼다.
1
2
3
4
5
6
7
8
9
10
11
private Rigidbody rb;
private void Awake()
{
rb = GetComponent<Rigidbody>();
}
private void Update()
{
rb.AddForce(Vector3.right);
}
GetComponent() 대신 TryGetComponent() 사용하기
GetComponent() 메소드는 할당에 성공하거나 실패해도 언제나 GC Allocation이 발생한다.
하지만 TryGetComponent()를 이용하면 GC 걱정 없이 깔끔하게 사용할 수 있으며,
할당 성공 여부를 bool 타입으로 리턴받을 수 있다.
TryGetComponent() 메소드는 유니티 2019.2 버전부터 사용할 수 있다.
이전 버전까지는 그대로 GetComponent()를 사용하면 된다.
Object.name, GameObject.tag 사용하지 않기
게임 오브젝트의 이름을 참조해야 할 때, .name 프로퍼티를 호출한다.
그리고 태그 비교를 해야 할 때, .tag 프로퍼티를 호출해서 ==, .Equals() 등으로 비교한다.
그런데 이런 호출 하나 하나가 전부 가비지를 한 개씩 생성한다.
.name으로 프로퍼티 Getter를 호출할 때마다 가비지 한 개,
.tag로 프로퍼티 Getter를 호출할 때마다 가비지 한 개.
예전부터 있었던 문제이고, 2021.1.16f1 버전에서도 직접 테스트해본 결과 동일했다.
UnityEngine.Object.name 프로퍼티를 살펴보면
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public string name
{
get
{
return GetName(this);
}
set
{
SetName(this, value);
}
}
[MethodImpl(MethodImplOptions.InternalCall)]
[FreeFunction("UnityEngineObjectBindings::GetName")]
private static extern string GetName(Object obj);
이런 식으로 구현되어 있다.
결국 오브젝트의 이름을 갖고 있는건 유니티 네이티브 영역이고,
이를 참조하려고 할 때마다 문자열을 새롭게 힙에 할당해 오기 때문에 가비지가 발생하는 것이다.
태그도 비슷한 방식으로 되어 있지만, 그래도 해결 방법이 있다.
gameObject.tag == "Player" 대신에
gameObject.CompareTag("Player")처럼
GameObject.CompareTag(string), Component.CompareTag(string) 메소드를 사용하면 가비지 생성을 방지할 수 있다.
결국 name 프로퍼티만 주의해서 사용하면 된다.
“절대로 쓰면 안된다”, 이런 것이 아니라
성능에 별 영향이 없는 것 같거나 다른 방안이 없으면 그냥 사용하고,
성능에 민감하면 다른 방법을 찾으면 된다.
비어있는 유니티 이벤트 메소드 방치하지 않기
Awake(), Update() 등의 유니티 기본 이벤트 메소드는 매직 메소드라고도 불리며,
스크립트 내에 작성되어 있는 것만으로도 호출되어 성능을 소모한다.
따라서 내용이 비어있는 유니티 기본 이벤트 메소드는 아예 지워야 한다.
protected virtual 등으로 지정하는 경우에도 혹시나 비워놓을 가능성이 있다면 지양하는 것이 좋다.
StartCoroutine() 자주 호출하지 않기
StartCoroutine() 메소드는 Coroutine 타입의 객체를 리턴하므로 GC의 먹이가 된다.
따라서 짧은 주기로 코루틴을 자주 실행해야 하는 경우, UniTask, UniRx 등으로 대체하는 것이 좋다.
UniTask는 Cancellation 관리가 번거로우므로, UniRx의 MicroCoroutine을 활용하면 좋다.
그리고 매 프레임 실행되는 코루틴의 경우(yield return null), 대신 Update를 사용하는 것이 성능상 효율적이다.
그런데 UniRx의 MicroCoroutine을 사용한다면 매 프레임 실행해도 된다.
코루틴의 yield 캐싱하기
1
2
3
4
5
6
7
8
private IEnumerator SomeCoroutine()
{
while(true)
{
// ...
yield return new WaitForSeconds(0.01f);
}
}
코루틴에서는 WaitForSeconds() 등의 객체를 yield return으로 사용한다.
그런데 위처럼 매번 new로 생성할 경우, 모조리 가비지 수집의 대상이 된다.
따라서 아래처럼 미리 변수에 담아 두고 사용하는 것이 좋다.
1
2
3
4
5
6
7
8
9
private IEnumerator SomeCoroutine()
{
var wfs = new WaitForSeconds(0.01f);
while(true)
{
// ...
yield return wfs;
}
}
메소드 호출 줄이기
메소드는 호출하는 것 자체만으로도 성능을 소모한다.
그런데 종종 가독성을 위해 비교적 간단한 문장도 메소드화하는 경우가 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
void Update()
{
// 1. 문장
bool b1 = transform.gameObject.activeSelf &&
transform.gameObject.activeInHierarchy;
// 2. 메소드 호출
bool b2 = IsFullyActive(transform);
}
bool IsFullyActive(Transform tr)
=> transform.gameObject.activeSelf &&
transform.gameObject.activeInHierarchy;
위의 경우, 동일한 문장을 여러 번 호출해야 한다면 대부분 메소드화해서 사용할 것이다.
메소드 호출 때문에 비용이 더 들지만 가독성을 위해 어쩔 수 없는 선택이라고 할 수 있다.
따라서 아래와 같이 사용할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
void Update()
{
if(IsFullyActive(transform))
{
// ...1
}
// ..
if(IsFullyActive(transform) && /* ... */)
{
// ...2
}
else
{
// ...
}
// ..
if(/* .. */ || /* .. */ && IsFullyActive(transform))
{
// ...3
}
}
그런데 ‘문장의 메소드화’와는 별개로, 이 코드에서 생각해봐야 할 점이 있다.
메소드 호출의 결괏값이 범위(메소드 블록 또는 라이프사이클 등) 내에서 항상 같다면?
따라서 두 가지 경우로 나누어 생각해볼 수 있다.
1. 해당 메소드 호출의 결괏값이 범위 내에서 달라질 수 있는 경우
IsFullyActive(transform)를 호출할 때마다 결과가 다를 수 있다면, 위처럼 사용하면 된다.
2. 해당 메소드 호출의 결괏값이 범위 내에서 항상 같은 경우
-
결국 항상 같은 값을 얻는데, 메소드를 여러 번 호출하는 것은 해당 메소드의 비용에 비례해서 그만큼의 손해를 보게 된다.
-
따라서 이런 경우에는 지역변수 또는 필드에 한 번의 메소드 호출로 값을 얻어 초기화한 뒤, 재사용 하는 방식을 선택해야 한다.
1
2
3
4
5
6
void Update()
{
bool isTransformFullyActive = IsFullyActive(transform);
// 블록 내에서 isTransformFullyActive 재사용
}
참조 캐싱하기
주로 프로퍼티 호출에 해당한다.
예를 들어,
1
2
3
4
5
6
7
void Update()
{
_ = Camera.main.gameObject;
_ = Camera.main.transform.forward;
_ = targetObject.transform.parent.gameObject.activeInHierarchy;
_ += Time.deltaTime;
}
이런 경우다.
프로퍼티는 필드가 아니다. 필드처럼 호출할 수 있는 메소드다.
실제로 내부적으로는 Setter, Getter 메소드로 이루어져 있으며,
당연히 메소드 호출만큼의 오버헤드가 발생한다.
심지어 위처럼 대상.프로퍼티.프로퍼티.프로퍼티.값 이렇게 이어지는 경우에는
호출하는 모든 프로퍼티가 각각 오버헤드로 이어진다.
따라서 이를 자주 호출해야 하는 경우에는 미리 참조로 캐싱해두는 것이 좋다.
예전보다 나아졌긴 하지만 심지어 Camera.main도 필드 참조보다 훨씬 비싸다.
메인 카메라로 등록된 참조를 바로 가져오는 친절한 친구가 아니라,
내부적으로 FindMainCamera() 메소드 호출을 통해 “MainCamera” 태그가 붙은 카메라들 중에 현재 렌더링을 담당하고 있는 카메라를 가져오는 프로퍼티다.
그래서 이렇게,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
private Camera _mainCam;
private GameObject _mainCamObject;
private Transform _mainCamTransform;
private GameObject _targetParentObject;
private float _deltaTime;
void Start()
{
_mainCam = Camera.main;
_mainCamObject = Camera.main.gameObject;
_mainCamTransform = Camera.main.transform;
_targetParentObject = targetObject.transform.parent.gameObject;
}
void Update()
{
_deltaTime = Time.deltaTime;
// ...
// Usages
_ = _mainCamObject;
_ = _mainCamTransform.forward;
_ = _targetParentObject.activeInHierarchy;
}
자주 호출하는 프로퍼티, 참조들은 최대한 해당 타입 그대로 필드에 담아 사용하는 것이 좋다.
Time.deltaTime도 캐싱하는 것은 과하다고 생각할 수 있는데,
Time.deltaTime 또한 내부 메소드 호출로 구현되어 있다.
여러 군데, 수십 군데에서 Time.deltaTime을 그대로 항상 호출하여 사용하면 그만큼의 메소드 호출 비용이 발생하는 것이니 항상 Update() 최상단에서 캐싱해서 사용하는 것이 좋다.
빌드 이후 Debug.Log() 사용하지 않기
Debug의 메소드들은 에디터에서 디버깅을 위해 사용하지만, 빌드 이후에도 호출되어 성능을 많이 소모한다.
따라서 아래처럼 Debug 클래스를 에디터 전용으로 래핑에서 사용할 경우, 이를 방지할 수 있다.
1
2
3
4
5
6
public static class Debug
{
[Conditional("UNITY_EDITOR")]
public static void Log(object message)
=> UnityEngine.Debug.Log(message);
}
Transform 변경은 한번에
position, rotation, scale을 한 메소드 내에서 여러 번 변경할 경우, 그 때마다 트랜스폼의 변경이 이루어진다.
그런데 트랜스폼이 여러 자식 트랜스폼들을 갖고 있는 경우, 자식 트랜스폼도 함께 변경된다.
트랜스폼의 변경 자체는 그리 큰 연산이 아닐 수 있으나, 한 번에 이루어질 수 있는 연산을 여러 번 하는 것은 당연히 그만큼의 성능 저하로 이어진다.
따라서 벡터로 미리 담아두고 최종 계산 이후, 트랜스폼에 단 한 번만 변경을 지정하는 것이 좋다.
또한 position과 rotation을 모두 변경해야 하는 경우 SetPositionAndRotation() 메소드를 사용하는 것이 좋다.
불필요하게 부모 자식 구조 늘리지 않기
하이라키가 너무 복잡할 경우, 나름의 카테고리별로 빈 부모 오브젝트를 만들고
자식 오브젝트를 넣어서 정리하는 경우가 많다.
그런데 이것도 최소한으로 나누고, 불필요한 부모-자식 관계를 늘리지 않는 것이 좋다.
자식 게임오브젝트의 트랜스폼은 부모 트랜스폼에 종속적이므로
부모 트랜스폼에 변경이 생기면 “모든” 자식 트랜스폼에 변경이 적용되기 때문에
성능에 악영향을 끼칠 수 있다.
따라서 부모-자식 관계는 필요한 만큼 최소한으로 구성해야 한다.
ScriptableObject 활용하기
게임 내에서 항상 공통으로 참조하는 변수를 사용하는 경우,
각 객체의 필드로 사용하게 되면 동일한 데이터가 객체의 수만큼 메모리를 차지하게 된다.
반면에 스크립터블 오브젝트로 만들고, 이를 필드로 공유하게 되면
객체의 수에 관계 없이 동일 데이터는 단 하나만 존재하게 되어 메모리를 절약할 수 있다.
참고 : 경량 패턴(Flyweight Pattern)
예시
게임 유닛의 HP(체력), MP(마력)을 정의한다.
각 유닛마다 현재 HP와 MP는 개별적으로 관리되어야 하므로 클래스의 멤버 변수로 저장하며,
동일한 유닛의 경우 MaxHP(최대 체력), MaxMP(최대 마력)는 공유될 수 있으므로 Scriptable Object로 저장한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public class GameUnit : MonoBehaviour
{
/* 개별 데이터 필드 */
private float hp;
private float mp;
// 공유 데이터 필드(Scriptable Object)
private GameUnitData data;
private void Awake()
{
/* 게임 시작 시 초기 HP, MP 값을 최대치로 설정 */
hp = data.maxHp;
mp = data.maxMp;
}
}
public class GameUnitData : ScriptableObject
{
public float maxHp = 100;
public float maxMp = 50;
}
필요하지 않은 경우, 리턴하지 않기
1
2
3
4
5
6
7
8
9
10
private int SomeMethod() // 정수 타입을 리턴하는 메소드
{
//...
return 0;
}
private void Caller()
{
SomeMethod(); // 메소드의 리턴값을 사용하지 않음
}
메소드를 호출하고 그 리턴값을 항상 사용하지는 않는 경우, 리턴값이 void인 메소드를 작성하는 것이 좋다.
리턴하는 것만으로 항상 성능 소모가 발생하며, 심지어 참조형인 경우 GC의 먹이가 된다.
(대표적으로 StartCoroutine())
new로 생성하는 부분 최대한 줄이기
클래스 타입으로 생성한 객체는 힙에 할당되며,
더이상 참조되지 않을 때 가비지 콜렉터에 의해 자동 수거된다.
그런데 너무 잦은 GC의 수거는 성능에 악영향을 끼칠 수 있다.
따라서 가능하면 한 번만 생성하고 이후에는 재사용 하는 방식을 사용하거나
최대한 new로 생성하는 부분을 줄이는 것이 좋다.
이럴 활용하는 대표적인 방법으로 버퍼(Buffer)의 사용,
메모리 풀링(Memory Pooling) 등이 있다.
버퍼의 사용은 어떤 기능 호출 시 매번 배열을 생성하여 가비지가 생기는 경우
매 수행마다 배열을 생성하는 대신, 미리 하나의 큰 배열을 생성하고
이 배열의 offset(index)을 이동하며 그곳에 할당하는 방식이다.
이 방식을 사용하는 대표적인 예시로 StringBuilder가 있다.
그리고 메모리 풀링은 동일한 타입의 많은 객체를 너무 자주 생성/파괴하는 경우
이를 미리 필요한 만큼 생성해놓고 재사용하는 방식이다.
유니티에서는 이 방식에서 파생된 오브젝트 풀링이 자주 사용된다.
오브젝트 풀링 사용하기
게임오브젝트의 생성과 파괴는 성능의 소모가 작지 않다.
따라서 생성과 파괴가 빈번하게 발생한다면(총알, 폭탄 등)
오브젝트 풀링을 통해 일정 개수의 게임오브젝트를 미리 생성하고
활성화/비활성화하여 재사용하는 방식을 활용하는 것이 좋다.
구조체 사용하기
- http://clarkkromenaker.com/post/csharp-structs/
- https://docs.microsoft.com/en-us/dotnet/standard/design-guidelines/choosing-between-class-and-struct
동일한 데이터를 하나는 구조체, 하나는 클래스로 작성할 경우 클래스는 참조를 위해 8~24 바이트의 추가적인 메모리를 필요로 한다.
따라서 데이터 클래스는 구조체로 작성하는 것이 좋으며, GC의 먹이가 되지 않는다는 장점도 있다.
그리고 구조체는 크기에 관계없이 항상 스택에, 클래스는 힙에 할당된다.
16byte를 초과하는 구조체가 힙에 할당된다는 루머를 본적이 있는데, 사실이 아니다.
스택과 힙, Value Type과 Reference Type
스택에 할당된다는 것, 힙에 할당된다는 것은 무엇일까?
스택은 지역 메모리, 힙은 전역 메모리라고 할 수 있다.
모든 Value Type(int, float, … , struct) 지역 변수는 스택에 저장된다.
그래서 해당 변수가 생성된 메소드 블록을 벗어나면 메모리에서 해제된다.
Value Type의 변수를 메소드에서 반환했을 때, 혹은 매개변수로 전달할 때
“값이 복제된다”라고 하는 이유가 바로 여기에 있다.
스택 메모리에 할당되었기 때문에 해당 영역(블록)을 벗어나면 사라진다.
그런데 어쨌든 이 값을 반환값이나 매개변수로 전달은 해야 하므로
기존 영역을 벗어나 새로운 영역에 도달했을 때, 그 영역에서 새롭게 할당하는 것이다.
이것이 바로 Value Type의 전달 방식이다.
반면에 Reference Type(Class Type)의 객체는 스택이 아닌 힙에 저장된다.
정확히 말하자면, 객체는 힙에 할당되고 이 힙의 시작 주소를 가리키는 변수가 스택에 할당된다.
그래서 영역(블록)을 벗어났을 때 이 스택의 변수는 사라지더라도
힙에 저장된 객체 자체는 사라지지 않는다.
그런데 C#에서는 힙에 저장된 이 객체가 더이상 그 어떤 변수에게서도 참조되지 않을 때,
조금 명확한 용어를 사용하자면 참조 카운트가 0이 됐을 때
가비지 콜렉터(GC)에 의해 자동으로 메모리에서 해제된다.
그리고 이 자동 메모리 수거가 발생할 때의 오버헤드가 문제될 수 있기 때문에
C#에서 다들 GC Call을 최대한 줄이려고 노력하는 것이다.
클래스 타입과 구조체 타입의 선택
그렇다고 모든 타입을 클래스가 아닌 구조체로 만든다?
이것은 또다른 문제가 된다.
구조체는 영역을 벗어나 전달될 때마다 복제된다.
만약 클래스 타입이었다면 단순히 참조 변수만 복제되고,
객체는 오버헤드 없이 전달될텐데
구조체라서 통째로 복제된다.
그래서 일정 크기 이상의 구조체는 차라리 클래스로 만들고,
아니면 복제/메모리 해제가 자주 발생할 수 있는지 여부에 따라
구조체/클래스 중 선택하고..
다양한 상황에 다양한 요소들을 고려하여 적절하게 선택해야 한다.
이는 정답이 없는 문제다.
그렇다면 어떻게 결정할 수 있을까?
경험 많은 프로그래머가 아니라면, 원칙을 세워두면 좋다.
- 16byte(예 : int, float 변수 4개) 이하의 데이터 클래스는 구조체로 만든다.
- 생성/해제가 자주 일어나면 구조체로 만든다.
- 생성/해제보다 전달(매개변수, 리턴)이 훨씬 자주 일어나면 클래스로 만들거나 매개변수 한정자
in을 사용한다.
간단한 원칙은 위와 같다.
기본적으로 1번의 원칙을 지키고, 2번과 3번은 설계 및 프로그래밍 진행 상황에 따라 고려하여 결정하면 된다.
컬렉션 재사용하기
List를 메소드 내에서 반복적으로 할당하여 사용하는 경우가 많다.
1
2
3
4
5
6
private void SomeMethod() // 여러 번 호출되는 메소드
{
List<Transform> transformList = new List<Transform>();
transformList.Add(...);
// ...
}
습관적으로 사용하게 되는 방식이지만, 이렇게 되면 가비지 콜렉터의 호출이 반드시 발생한다.
따라서 다음과 같이 변경하여 사용하는 것만으로 컬렉션에 할당되는 가비지를 줄일 수 있다.
1
2
3
4
5
6
7
8
transformList = new List<Transform>();
private void SomeMethod()
{
transformList.Clear();
transformList.Add(...);
// ...
}
실제로 이렇게 바꿨을 때, 아래처럼 가비지를 굉장히 줄인 경우가 있었다.
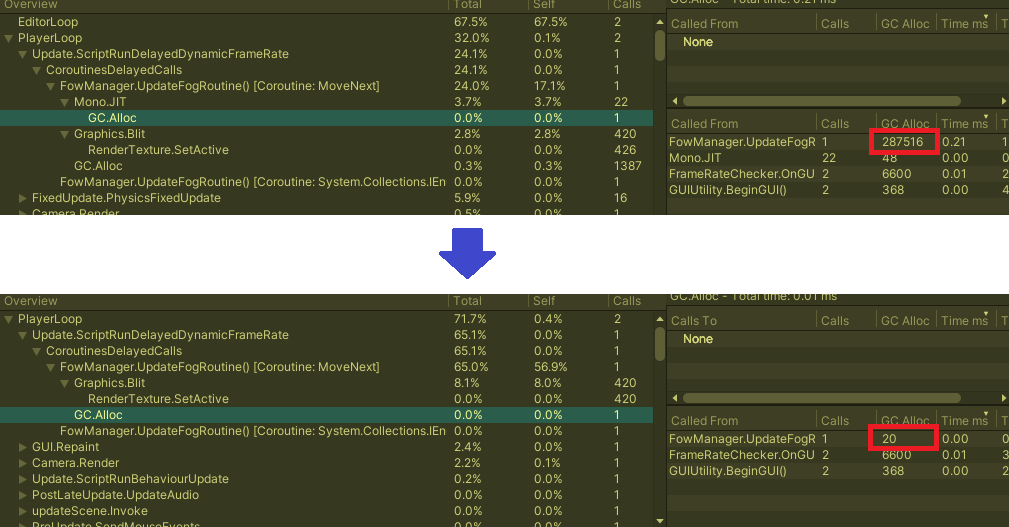

가비지 할당(GC.Alloc) 자체가 성능에 큰 영향을 미치지는 않지만,
결국 가비지가 수집(GC.Collect)될 때 성능에 많은 영향을 끼치게 되므로 반드시 신경써야 하는 부분이다.
List 사용할 때 주의할 점
만약 배열을 사용할 때, 처음에는 비어있는 배열을 생성하고
새로운 값을 하나씩 넣을 때마다 크기가 조금 더 큰 배열을 만들고,
기존의 배열을 통째로 복제하는 방식으로 사용한다고 생각해보자.
이건 너무 비효율적이라고 생각할 수 있다.
C#의 가변 배열인 List<T>는 내부적으로 배열로 구현되어 있다.
그리고 내부 구현은 정말로 위에서 설명한 그대로 되어있다.
new List<T>()로 생성하면 크기가 0인 배열을 생성한다.
그리고 .Add()를 통해 요소를 하나씩 추가할 때마다 처음에는 크기가 4인 배열을 생성하고
배열이 가득찰 때마다 현재 배열의 두 배 크기의 새로운 배열을 생성하며,
기존의 배열을 그대로 복제해온 뒤 마지막 위치에 새로운 요소를 집어넣는 방식이다.
그래서 리스트를 생성할 때, 사용될 영역의 크기를 미리 알고 있다면
new List<T>(100) 처럼 개수를 미리 지정하는 것이 좋다.
그러면 내부적으로 그만큼의 크기를 갖는 배열을 미리 할당하여,
.Add()를 하더라도 기존의 배열 전체를 통째로 복제하는 것을 방지할 수 있다.
이미 생성된 리스트라면 .Capacity 프로퍼티에 크기 값을 넣어주면 된다.
StringBuilder 사용하기
스트링의 연결(String Concatenation) 또는 다른 타입 값을 문자열에 합치는 스트링 포맷팅(String Formatting)이 자주 발생하는 경우, StringBuilder를 활용하는 것이 좋다.
1
2
string a = "a1";
a = "a2";
스트링에 상수 문자열을 초기화 하는 것은 가비지를 생성하지 않지만,
1
2
3
4
5
6
7
8
9
string strA = "a";
string strB = "b";
strA = "a" + "b";
strA = strA + strB;
strA = $"{strB}c";
string formatted1 = $"{123} + {234} = {357}";
string formatted2 = string.Format("{0} + {1} = {2}", 123, 234, 357);
스트링끼리 연결하거나 스트링 포맷팅을 통해 런타임에 새로운 스트링을 만드는 경우에는 가비지가 생성된다.
1
2
3
4
5
6
7
8
9
StringBuilder sb = new StringBuilder(100);
sb
.Append(123)
.Append(" + ")
.Append(234)
.Append(" = ")
.Append(357);
string sbString = sb.ToString();
따라서 이렇게 StringBuilder를 사용하는 것이 좋다.
그렇다고 StringBuilder 객체를 매번 생성하면 이 또한 가비지가 되므로,
StringBuilder 객체는 한 번만 생성하여
.Clear()로 내부를 초기화하면서 항상 재사용해야 한다.
LINQ 사용 시 주의하기
- https://medium.com/swlh/is-using-linq-in-c-bad-for-performance-318a1e71a732
- https://www.jacksondunstan.com/articles/4840
LINQ는 개발자에게 굉장한 편의성을 제공해주며, 대개 성능이 크게 나쁘지는 않다.
하지만 정확히 이해하고 사용할 필요가 있다.
LINQ의 대부분의 연산자는 중간 버퍼(일종의 배열)를 생성하고, 이는 모조리 가비지가 된다.
그러니까 LINQ 연산자 한두개쯤 사용해서 가능한 것을
가독성이나 모종의 이유로 여러 번 나누어 처리하게 되면 모두 불필요한 성능 저하의 원인이 된다.
성능에 민감하거나 매프레임 호출되는 부분에서 LINQ를 사용하고 있었다면,
가능하면 최대한 LINQ의 사용을 자제하고 직접 구현하는 것이 좋다.
물론 하드 코딩으로 매번 구현하기보다, LINQ를 대체할 수 있는 API를 구축해서 재사용하는 것이 현명할 것이다.
잘 모르겠다면, 간단한 규칙을 정해보면 된다.
- 빠르게 구현해야만 하는 상황(프로토타입 개발 등)인가? -
LINQ사용 - 성능에 민감하지 않은 코드(에디터 전용 코드 또는 작은 코드 등)인가? -
LINQ사용 LINQ의 편의성 또는 가독성이 꼭 필요한가? -LINQ사용- 매프레임 호출되거나, 성능에 민감한 부분인가? -
LINQ사용하지 않기
솔직히 LINQ 때문에, 혹은 다른 이유로 가비지가 많이 생성된다고 해서 ‘그 즉시’ 문제가 발생하지는 않는다.
하지만 게임 플레이 도중 영문을 모르게 느닷없는 프리징(멈춤)이 발생하고,
프로파일링을 해봤더니 GC.Collect()가 반갑게 맞아주고 있다면
업보가 돌아왔다고 생각하면 된다.
박싱, 언박싱 피하기
박싱(Boxing)은 값 타입이 참조 타입으로 암시적, 또는 명시적으로 캐스팅되는 것을 의미한다.
언박싱(Unboxing)은 참조 타입이 값 타입으로 명시적으로 캐스팅되는 것을 의미한다.
이 때 중요한 것은, 박싱과 언박싱이 단순 할당보다 성능이 매우 나쁘다는 것과 참조 타입은 힙에 할당되어 GC의 먹이가 될 수 있다는 점이다.
1
2
3
4
public static class Debug
{
public static void Log(object msg) { /* ... */ }
}
유니티 엔진을 사용하면서 가장 친숙한 메소드인 Debug.Log()이다.
그리고 항상 박싱이 발생하는 대표적인 예시라고 할 수 있다.
파라미터의 타입이 object이기 때문에, 어떤 값 타입을 넣어도 참조타입인 object 타입으로 박싱된다.
이렇게 메소드 매개변수로 object 타입을 사용하거나 박싱을 유도하는 방식은 최대한 지양해야 한다.
따라서 이를 피할 수 있는 대표적인 방법으로, 제네릭이 있다.
제네릭은 객체 생성 또는 메소드 호출 시 제네릭 타입이 하나의 타입으로 고정되기 때문에, 박싱과 언박싱을 피할 수 있다.
Enum HasFlag() 박싱 이슈
[Flags]를 사용하는 enum의 경우, HasFlag()를 사용하면 간편히 포함관계를 파악할 수 있다.
하지만 이 때 어떤 enum 타입이 System.Enum으로 변환되면서 박싱이 발생한다.
따라서 이를 피하기 위해서는 다음과 같은 확장 메소드를 만들어 사용하는 것이 좋다.
1
2
3
4
public static bool HasFlag2<T>(this T self, T flag) where T : Enum
{
return (self & flag) == flag;
}
참고 : 해결된 박싱 이슈
- foreach 루프 박싱 이슈
- foreach를 사용할 경우 매번 24byte의 추가적인 가비지가 발생한다는 이슈
- 현재 버전에서는 해결되었다고 한다.
- Dictionary의 키로 Enum을 사용할 경우 박싱 이슈
- 역시 .Net 4.x 버전에서 해결되었다고 한다.
비싼 수학 계산 피하기
-
나눗셈 대신 곱셈
나눗셈이 곱셈보다 느리다는 것은 흔히 알려져 있는 사실이다.
그런데 곱셈을 해도 되는 부분에 나눗셈을 사용하는 코드가 의외로 자주 보인다.
1.0f / 2.0f 보다 1.0f * 0.5f가 빠르다. 꼭 기억하자.
나눗셈을 어떻게 곱셈으로 대체할지 고민이 될 수도 있는데,
간단한 규칙을 정하면 편하다.
1
result = a / b;
위와 같이 사용하는 식이 있을때, 다음과 같이 규칙을 정한다.
-
만약
b값이 자주 변한다면 나눗셈을 그대로 사용한다. -
b값이 상수이면c = 1 / b상수 또는 변수를 선언하고,
a / b대신a * c를 항상 사용한다. -
b값이 일정한 주기로 바뀐다면, 바뀌는 순간마다c = 1 / b로 담아놓고
a / b대신a * c를 항상 사용한다.
-
If-else vs 삼항 연산자
직접 비교해본 결과, 성능 차이가 거의 없었다.
가독성만 생각해서 사용하면 된다.
-
System.Math.Abs vs UnityEngine.Mathf.Abs vs 삼항 연산자
1
2
// 삼항 연산자를 이용한 Abs
(x >= 0) ? x : -x;
삼항 연산자가 압도적으로 빠르다.
닷넷 콘솔 디버그 빌드에서는 Math.Abs보다 삼항 연산자가 두 배 정도 빨랐고,
릴리즈 빌드에서는 여섯 배 정도 빨랐다.
심지어 삼항 연산자를 함수화 해도 Math.Abs(), Mathf.Abs()보다 빨랐다.
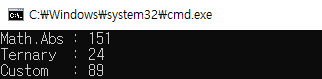
그리고 유니티 엔진에서도 비슷한 결과를 얻을 수 있었다.
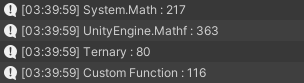
가독성을 위해서라면 메소드를 사용할 수 있겠으나,
작은 성능에도 아주 민감하다면 삼항 연산자를 사용하는 것이 좋다.
-
Mathf.Abs()가 느린 이유
UnityEngine.Mathf.Abs(float)를 예시로 내부 구현을 살펴보면
1
2
3
4
5
6
7
8
9
10
11
// UnityEngine.Mathf
using System;
/// <summary>
/// <para>Returns the absolute value of f.</para>
/// </summary>
/// <param name="f"></param>
public static float Abs(float f)
{
return Math.Abs(f);
}
이렇게 System.Math.Abs(float)를 호출한다.
그럼 System.Math.Abs(float)를 살펴보면
1
2
3
4
5
6
7
8
9
10
11
12
// System.Math
using System.Runtime.CompilerServices;
using System.Security;
/// <summary>단정밀도 부동 소수점 수의 절대 값을 반환합니다.</summary>
/// <param name="value">
/// <see cref="F:System.Single.MinValue" />보다 크거나 같지만 <see cref="F:System.Single.MaxValue" />보다 작거나 같은 숫자입니다.</param>
/// <returns>0 ≤ x ≤<see cref="F:System.Single.MaxValue" /> 범위의 단정밀도 부동 소수점 숫자 x입니다.</returns>
[MethodImpl(MethodImplOptions.InternalCall)]
[SecuritySafeCritical]
[__DynamicallyInvokable]
public static extern float Abs(float value);
이렇게 네이티브 호출로 이어진다.
UnityEngine.Mathf는 대부분 이렇게 구현되어 있기 때문에 비교적 느릴 수 있다.
물론 큰 차이는 아니겠지만, 자주 사용되는 연산이 있다면 한 번쯤 고려해보는 것이 좋다.
결론적으로, 동일 연산에 대하여
-
직접 계산하는 것이 가장 빠르다.
-
System.Math는 웬만해서 UnityEngine.Mathf보다 빠르다.
Camera.main
위에서 잠깐 언급했지만, Camera.main을 매프레임 참조하는 것은 생각보다 성능이 좋지 않다.
내부적으로 FindMainCamera() - FindWithTag("MainCamera") - … 이렇게 호출이 이어지고,
모든 오브젝트 목록을 찾고 거기서 다시 MainCamera 태그가 붙은 오브젝트의 목록을 찾아서
그 중에서 메인 카메라를 찾는 방식이다.
유니티 에디터 2020.2 버전부터는 개선되었다고 한다.
그런데 아직도 2019, 심지어는 2018이나 그 이하 버전을 사용하는 경우도 굉장히 많으므로
이런 이슈는 버전에 맞게 반드시 고려해야 한다.
벡터 연산 시 주의사항
아주 간단하고 사소하지만, 성능에 영향을 미칠 수 있는 문제가 있다.
1
2
3
Vector3 vec = new Vector3(1f, 2f, 3f);
float a = 4f;
float b = 5f;
위와 같이 벡터와 스칼라 변수가 있다.
스칼라는 단순한 하나의 값을 갖는 변수 또는 상수를 의미하고,
벡터는 여러 스칼라 값을 갖는 변수 또는 상수를 의미한다.
Vector3는 세 개의 값을 갖는다.
1
Vector3 vec2 = vec * a * b;
벡터 연산을 하다 보면, 무심코 위와 같이 연산할 수 있다.
얼핏 보기에는 아무런 문제가 없으나, 사소하면서도 중요한 문제가 있다.
Vector3는 x, y, z 세개의 값을 갖는다.
따라서 다른 스칼라 값과 연산을 하게 된다면
vec * a 연산은 실제로
1
new Vector3(vec.x * a, vec.y * a, vec.z * a)
이렇게 벡터 내의 모든 성분이 각각 스칼라와 연산되어, 총 세 번의 연산이 발생한다.
그리고 아직 * b가 남았으므로, 연이어 표현하자면
1
2
Vector3 temp = new Vector3(vec.x * a, vec.y * a, vec.z * a);
Vector3 vec2 = new Vector3(temp.x * b, temp.y * b, temp.z * b);
이렇게 마찬가지로 벡터의 각 성분마다 한 번씩, 다시 세번의 연산이 이루어진다.
최종적으로 여섯 번의 스칼라 곱셈 연산이 발생한다.
그런데 만약 순서를 바꾸어
1
Vector3 vec2 = a * b * vec;
위와 같이 스칼라부터 연산한다면
1
2
float temp = a * b;
Vector3 vec2 = new Vector3(vec.x * temp, vec.y * temp, vec.z * temp);
이렇게 네 번의 스칼라 곱셈으로 연산이 이루어진다.
결과적으로 동일한 값을 도출하지만, 스칼라부터 연산하는 것이 성능 상 훨씬 이득이다.
따라서 이를 습관화할 필요가 있다.
요약
- 벡터와 스칼라 연산은 스칼라부터 모두 계산한 뒤에, 벡터와 계산하는 것이 성능 상 매우매우 좋다.
1
vector * scalar * scalar
위와 같은 연산은
1
scalar * scalar * vector
또는
1
vector * (scalar * scalar)
이렇게 스칼라부터 연산하도록 해야 한다.